Bayesian A/B Testing by SplitMetrics
 Lesia Polivod
Lesia Polivod  Lesia Polivod
Lesia Polivod The SplitMetrics team is happy to introduce the freshly released Bayesian A/B testing.
The Bayesian approach can be useful in cases where marketers have some beliefs and knowledge to use as a primer assumption (in our case, it is informed prior in the default settings) that helps algorithms calculate the probability of related events to the likelihood of a certain outcome. Hence, users can make faster decisions with lower costs of experiments by incorporating beliefs or knowledge as part of the experiment, compared with the Frequentist or Sequential methods.
The benefits of the Bayesian approach in SplitMetrics are that users can find indirect control over the risk because they can control the expected loss stopping rule (threshold of caring).
The stopping rule – stops the test to save budgets once the winner or underperformer is obvious.
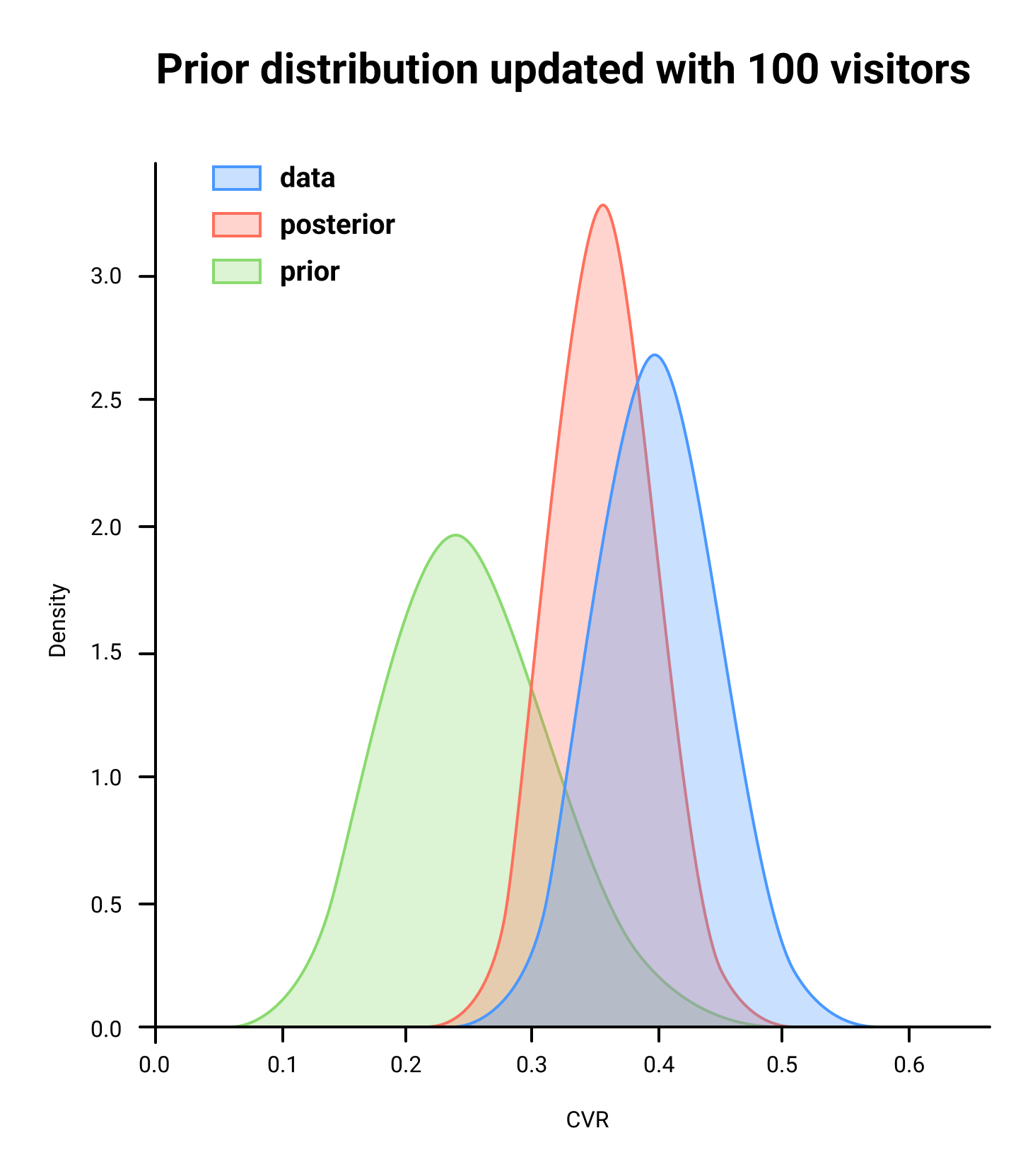
A Bayesian test starts from a weak prior assumption about the expected conversion (prior distribution). The prior may fix the noise at the beginning of the test when the sample size is low. As the test progresses and more visitors participate, the impact of the prior fades.
Leverage your A/B testing with the Bayesian approach as an industry gold standard for iterative A/B testing and growth hacking with less traffic required.
Otherwise, if criteria don’t meet in the growth-hacking model.
There is a chance of getting stuck with a slight change (deterioration). Hence, it can accumulate a significant effect over time.
The possible flaws of Bayesian in some contexts are the side effects of treating control and test groups equally and controlling for cost/value rather than False Positive/False Negative error rate.
Or if a conservative strategy is rationally justified
If you want a strict rule limiting the team’s discretion, you should try the Sequential approach with a standard p_value threshold.
Even if there is a slight difference between variations in the Bayesian approach, the one that looks at least a little better at the moment will be selected as recommended. Lean towards a conservative strategy with the Sequential approach that ensures statistical significance data for each variation to make conclusions.
Online cost optimization
Early stopping by toc (threshold of caring) with the expected loss tolerance if there’s overperformer, underperformer, or approximately equal with the opportunity to spend fewer budgets on a test.
The Frequentist test came from the academic setup, where a false positive result is a major failure by default: you mislead the entire scientific community by reporting one. Thus, you are conservative by default: you prefer sticking to the current state and sacrificing exploitation for the low chance of being even marginally wrong.
Interpretability
The Bayesian A/B testing in the SplitMetrcis platform showcase a winning probability for experiment interpretability.
Unleash the full potential of app growth hacking.


